Overview of Mobile E2E Testing
1. Introduction
End-to-end (E2E) testing is a software testing strategy that verifies the system integration from start to finish, including apps, backend services, and other related components; to ensure everything functions as expected altogether. Compared to unit tests, E2E tests are often fewer in number due to their complexity and maintenance costs. This type of testing is even more uncommon in mobile development where special setups are often required.
This blog post aims to provide a quick overview of mobile E2E testing and some opinionated architecture suggestions for incorporating E2E testing into your engineering process.
2. Background
2.1. Types of Testing
The testing pyramid model categorizes automated tests into three levels: unit tests, integration tests, and E2E tests.
Unit tests, often focusing on a single functionality, are the most prevalent due to rapid implementation and execution. Meanwhile, E2E tests - sitting atop the pyramid, offer wider coverage due to higher level of integration, but fewer in quantity due to their greater complexity. Integration tests, lying in the middle, compromises the other two.
In mobile development, we can view UI tests with a mock backend as integration tests (also sometimes called “workflow UI tests”), and UI tests with real backend as E2E tests. When running UI tests, the test process starts the app and performs UI actions (taps, swipes, scrolls, etc.) just like how a real user interacts with the app.

2.2. E2E Testing in Mobile Development
A testing device is connected to a computer (or the host machine, in case of simulators). With some special setup, we can perform test actions (for instance, launching an app, or querying app elements) on the connected device via this computer.
In practice, E2E testing on a device usually involves:
- Maintaining a server (with a dedicated port) on this computer that accepts incoming requests from the outside.
- For each test request, this server performs corresponding test actions on the connected device.
For convenience, we’re gonna use the term “test server” to refer to the server performing test actions on devices. When testing with Appium, we start an Appium server to communicate with devices. In this context, the Appium server can be considered the test server we’ve described.
3. Architecting E2E Testing Solutions
3.1. Choosing Your Test Framework
We can use native frameworks such as XCUITest for iOS and Espresso/UIAutomator for Android. One clear advantage of this approach is the ability to leverage our programming language of expertise and potentially reuse native component code. However, this method may not be suitable for larger-scale projects due to several reasons.
First, we need to maintain separate test codebases for each platform (iOS and Android), which can be time-consuming and less cost-effective.
Second, E2E tests are not always maintained by native engineers. For instance, in one of my previous companies, E2E tests were primarily driven by automation engineers. Adopting a native test framework in such cases introduces an additional learning curve for them, increasing onboarding and maintenance costs.
Finally, E2E testing often involves more than just native apps; it can also include interactions with backend services or tools to manage simulators and devices. Implementing such tasks using native code can be less straightforward.
Write Once for All Platforms
Given the complexity of E2E tests, many opts for a cross-platform test framework. A few candidates stand out.
The most popular choice is Appium, an open-source UI automation solution for many platforms including mobile, browser, desktop, etc. Appium has been around for a long time and is possibly the most mature options available. We will primarily focus on using Appium in future posts about E2E testing.
One of Appium’s advantages, as compared to others, is that we can write test cases in our preferred language, thanks to the availability of Appium clients in various languages such as Python, Ruby, Java, JavaScript, etc. Additionally, Appium offers a wide range of features, many of which are driven by its active community.
Another option is Maestro, which was first introduced in 2022. Unlike Appium, Maestro emphasizes on declarative syntax-based test cases. This reduces the learning curve as engineers only need to declare test steps in a YAML file. No need to learn other languages as compared to the Appium. However, this approach comes with some trade-offs. We will compare the two declarative vs. scripted approaches in section 3.3.
For React Native projects, Detox is a widely-used tool. This framework is specifically tailored for React Native apps, offering rich integrations with the React Native ecosystem. While I haven’t personally used Detox, my research suggests that it performs slightly better in terms of execution time because it does not rely on WebDriver. The expectations run directly on the app process, rather than a separate test process. This reduces the overhead IPC (inter-process communication) cost and allows various backdoors for testing. As a result, it’s an excellent fit for React Native-focused projects.
3.2. Choosing Your Language
As mentioned above, a common choice for writing once for all platforms is using Appium together with a scripting language of your interests (to write your tests).
You can choose any supported language that you’re comfortable with. If you don’t have anything in mind, I personally recommend Python, which is my favorite.
Once you’ve got your tests working in one language, it should be relatively easy to adapt them in another language. My advice is to focus on the extensibility of the test framework in your chosen language and its plugin ecosystem. Having worked with both Ruby’s RSpec and Python’s Pytest frameworks, I would say I love Pytest a lot more. It simplifies the process of writing and executing tests. And its rich plugin architecture is a game-changer. With Pytest, you can easily integrate advanced features like fancy reports or parallel testing simply by installing a plugin.
In two of my previous companies, we both used the Appium + Pytest combination as the core stack for E2E testing.

3.3. Declarative vs. Scripted
Some choose Maestro for its declarative syntax to write tests. A Maestro test case looks like this:
# search-flow.yml
appId: org.wikimedia.wikipedia
---
- launchApp
- tapOn: Skip # dismiss tutorial
- tapOn: Search Wikipedia
- inputText: Facebook
- assertVisible: Facebook is a social media and social networking service owned by Meta
This looks appealing as test cases are written in human-readable format. While it reduces the learning curve (for how to write Python or Ruby code properly), it’s not a perfect choice in terms of flexibility.
Although Maestro supports running a custom script (in JavaScript) or even conditional execution, this might not be sufficient for large-scale projects with complex test cases. For instance, in cases where retries are necessary to mitigate flakiness, implementing such logic within Maestro can be cumbersome. Meanwhile, with a scripted test case (such as one written with Pytest), this can be achieved by simply adding a custom @retry decorator to the step method.
Another challenge arises with A/B testing or non-deterministic features. If the test account is whitelisted for a specific rollout, the test flow may need to change. While handling those conditions is possible, the test cases would then look more complicated and no longer be concise and maintainable. In these scenarios, scripted test cases offer more flexibility and scalability.
Some test frameworks, like Cucumber, adopt a hybrid solution of both declarative and scripted: test specs written in a human-readable language, test implementation written in a scripting language.
For me, I prefer the scripted approach as it offers greater flexibility and scalability. Readability can be easily achieved by structuring test code properly.
3.4. Client-Server Testing vs. Server-Side Testing
There are two types with regards to where tests are executed: client-server testing and server-side testing. In this context, “server” refers to the server/machine that manages your devices or simulators.
Server-Side Testing
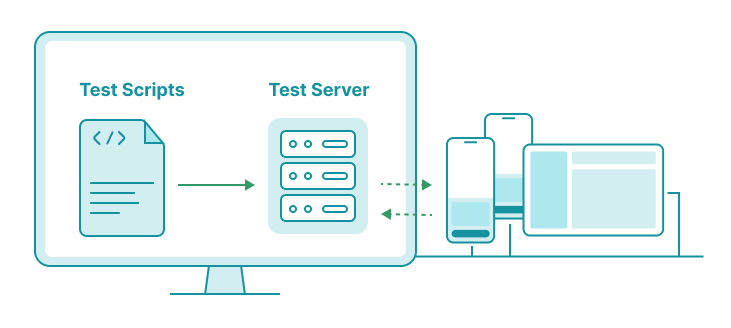
In this model, your tests run on the same machine as the test server (physically, or virtually). Testing with Appium on AWS Device Farm works this way. When creating a test run, you are prompted to upload a test package to the Device Farm. Your tests then execute on the Device Farm’s test runners.
Running tests this way is similar to running tests locally. The tests communicate directly with the test server, which runs on the same machine. This ensures a more stable connection between the test code and the test server.
Moreover, since you’re running code on the test machine (which connects to the device), you can directly operate on the device directly without going through the test server. For example, you can simply run a shell command tidevice -u <UDID> reboot in your code to reboot the phone if needed.
Client-Server Testing
This is often the case for testing on CI environments. Typically, CI runners are hosted on remote machines (either in-house or by third-party vendors) and may not connect to your devices. Therefore, a common design is to have dedicated machines to host the testing devices, with your tests connecting to those devices via a test server.
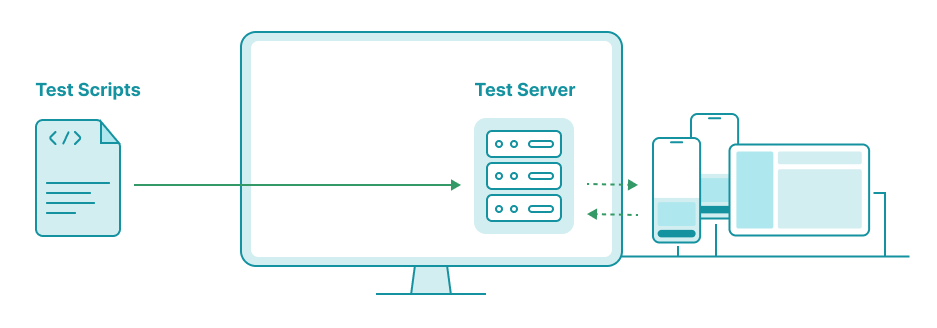
In this setup, network connection between CI runners and test servers is a key consideration. For example, a test case verifies the presence of an element with a timeout of 1s but the request to the test server might itself take up to 3s, causing test failures.
When writing tests, you also need to reason whether this specific code runs on CI runners or test servers. For instance, you cannot reboot a device by running the tidevice -u <UDID> reboot shell command directly from the CI runner, as the runner does not connect to the device. In such cases, test actions are limited to the APIs exposed by the test servers.
Take testing with Appium for example: your test cases can only interacts with devices through Appium’s APIs. However, these APIs might not cover all your needs. For example, Appium does not have a device reboot API as of now (Dec 2024). To address such limitations, you can deploy a supplementary test server alongside the Appium server, which will be discussed further in upcoming posts. Take testing with Appium for example: your test cases can only interacts with devices through Appium’s APIs. However, these APIs might not cover all your needs. For example, Appium does not have a device reboot API as of now (Dec 2024). To address such limitations, you can deploy a supplementary test server alongside the Appium server, which will be discussed further in upcoming posts.
3.5. Real Devices vs. Simulators, Device Farm
Whether to test on simulators or devices (or both) depends on your testing strategies and available resources.
Testing on devices
Testing on devices involves more complex setup, from app signing to managing devices (ex. which ones are available or occupied). Such a device management solution is often called “device farm” solution.
Several 3rd-party device farm solutions are available, such as BrowserStack, Sauce Labs, Kobiton, AWS Device Farm, etc. These services are usually pay-as-you-go or subscription-based, with pricing models depending on the number of users or parallel test sessions. Some providers allow you to add private devices, so you can use both their devices and your own. While 3rd-party services are convenient, many teams are reluctant to use due to their cost.
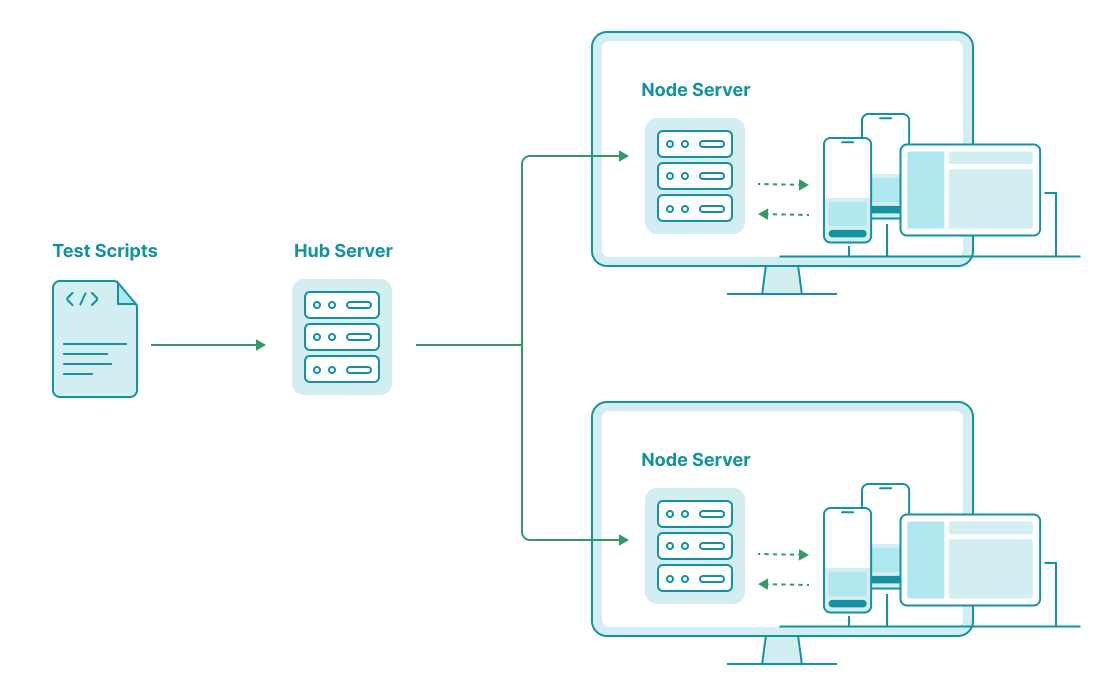
Alternatively, you can orchestrate your own device farm using open-source tools. In my previous company, we used Sonic to manage in-house devices. Other options include Appium Device Farm. Both allow you to occupy or release a device, start a test session, and even operate on a device via a Web UI.
Additionally, these tools support setting up devices across multiple nodes/machines. This is crucial for splitting the server load and establishing office-based or team-based device farms.
A perk of using an in-house device farm is the level of control over your devices. You can quickly intervene to resolve device issues, making tests more stable. However, this comes with an overhead maintenance cost. For example, we’ve faced the issues like unstable cables causing some iOS devices being disconnected. Or, the “Trust This Computer” popup appears on devices (usually after reconnected to the computer) although the permission was granted before. Even worse, some devices are hosted in distant locations, such as our Hong Kong office, which requires manual operation to resolve the issues.
Testing on simulators
Testing on simulators is generally simpler. It’s similar to how engineers test the app during feature development. On simulators, you can run various simulations, such as updating device location, or triggering push notifications, which simplifies some test setups.
Testing on simulators is strategic when CI resources are abundant. For instance, in one of my previous companies, we had over 120 MacStadium (Gitlab) runners for iOS. Each runner is a MacOS machine that could be utilized for E2E testing by starting an Appium server on the runner, and run tests with the given local server. This approach essentially follows the “server-side testing” model we discussed earlier. It’s just that the test server, in this case, runs on a CI runner.
In the upcoming posts, we will explore more about device farm solutions.
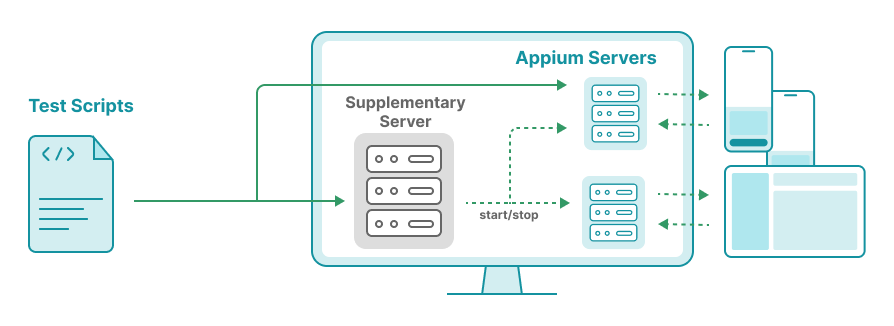
3.6. Shared Appium Server vs. Multiple Servers for Multiple Devices
We manage over 20 iOS devices in our company, most of which are connected to a Linux machine located in our Hong Kong office. Initially, we set up a shared Appium server to handle all testing on these devices. Tests could connect to this server at http://10.10.10.10:4723, for example, where 10.10.10.10 is the IP address of the Linux machine.
Problems arise when we troubleshoot issues on the server side. When multiple test sessions run simultaneously, Appium logs for those sessions are merged into a single log file. This makes it extremely difficult to isolate and analyze logs for a specific test on a specific device.
Another challenge is maintaining the consistent uptime for the shared server. We observed a significant degraded test performance due to Appium memory leaks. Typically, one Appium server process consumes 150–200MB. For multiple devices, the combined usage is still manageable (< 2GB). However, over time - within 1-2 weeks, the memory usage gradually increased to 10GB (>100% memory of the machine’s memory), resulting in very slow Appium response times. To recover, we had to restart the Appium server, which caused ongoing test sessions to fail.
To address these challenges, we implemented a solution where each test session is assigned a dedicated Appium server. This approach ensures isolation between test sessions and better resource management.
- Start a dedicated Appium server at the beginning of each test session.
To avoid port collisions, we can assign a unique port to each device. For example, for a device with ID
1234, the server URL becomeshttp://10.10.10.10:11234(port: 10000 + device ID). - Use the dedicated server URL as the WebDriver URL for your tests.
- Stop the Appium server at the end of the session to release unused resources.
This start-and-stop mechanism can be orchestrated using a supplementary server (referenced in section 3.4).
4. Challenges
E2E testing inherits two prominent problems of UI testing: flakiness and slow execution time. This also means solutions for these two problems in UI testing might be applicable to E2E testing as well.
4.1. Flakiness
Flakiness can be caused by various reasons, some of which were discussed in this post. It is far more prevalent in E2E tests than in workflow UI tests.
Unlike workflow UI tests, where network requests are often mocked, E2E tests require communication with real APIs. This increases the potential for failures, not just from the app’s requests but also from internal APIs used for test setup, such as preparing test data. As a result, you might need to add retries to certain test actions to ensure stability.
Device-related issues are harder to manage. For example, on iOS, Appium relies on WebDriverAgent (WDA), which starts a web server on the device. This connection can be unstable during a session, leading to many test failures.
Given that flakiness is unavoidable, what we can do is automatically detecting flaky tests, and possibly skipping them during critical runs to avoid unnecessary disruptions.
4.2. Slow Execution Time
Execution time of an E2E test can vary from less than 1m to more than 5m. Let’s assume an average test time of 2m. For a project with 50 test cases, this would mean a total time of 1h40m to complete the whole test suite, not to mention the overhead time of test retries.
One common strategy to reduce test execution time is parallelization. This is often the case for CI execution as we rarely run all test cases on local.
Parallel test executions in a pipeline can be done by having multiple test jobs. Each handles a batch of the test suite. In each job, we can also achieve the parallelism by running a subset of tests in parallel threads. If using Python, we have a Pytest plugin called pytest-xdist that distributes tests across multiple threads to speed up the overall execution.
A good test distribution should ensure the balance of execution time across batches.

One way to do this is by using execution time data from previous runs to heuristically split the test cases.
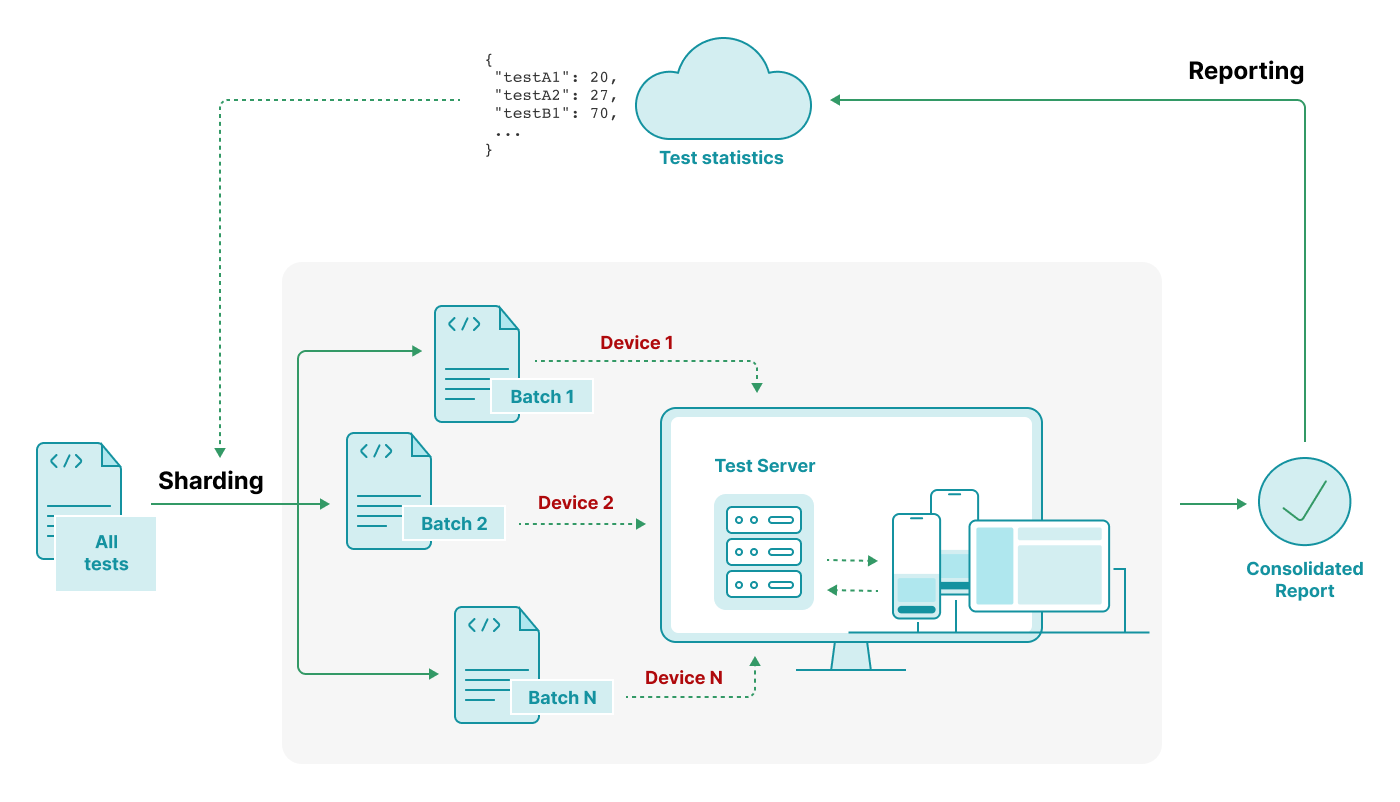
Occasionally, you may notice that test actions become slower due to degraded performance on the test server. For example, when a test server is handling concurrent executions of 10 devices, each consuming certain amount of CPU/memory, the responsiveness may be slower. Therefore, it’s useful to add instrumentations in your tests (ex. by measuring the response time of querying an element) to monitor test performance and identify bottlenecks as well as unusual behaviors.
5. Common Practices
5.1. Backdoor for Testing
A common backdoor for testing is simulating the logged-in state. This is important to reduce the execution time because a user login journey might take up to 30s or even more. A typical solution is obtaining the JWT token through internal APIs and injecting it into the app via the process environment. The app can then retrieve the token simply by ProcessInfo.processInfo.environment["JWT_TOKEN"] (in iOS) and bypass the login flow.
In fact, many backdoors can be implemented this way, ie. injecting values into the process environment. For instance, you can speed up animations in the app by adjusting the CALayer’s speed, hence reducing the execution time.
if isE2E, let layerSpeed = ProcessInfo.processInfo.environment["LAYER_SPEED"].map(Float.init) {
UIUtils.windows.forEach { $0.layer.speed = layerSpeed }
}
Another use case is controlling A/B testing features in the app. Ideally, you should programmatically whitelist your test account for a certain feature, perhaps using internal APIs. If there’s no such a direct way, you can toggle features on and off by manipulating the process environment or by using configuration files (which can be pushed to the device).
5.2. Designing Test Suite
How you design your test cases can significantly impact the overall execution time. For example, in a project with 50+ test cases, you might consider having a dedicated test case for verifying the user login flow, while the rest of the tests can assume the user is already logged in. This saves time while still ensuring full coverage for app flows. The general formula is:
- A dedicated test runs the full (high-cost) flow.
- The majority of tests run the shortcut (low-cost) flow.
Similarly, if a feature’s entry point is difficult to reach from the home screen, you could use deep links (if supported) to directly navigate to the feature. This helps save time and reduce the chances of failure on intermediate screens.
5.3. Integrating to CI/CD Workflows
Whether to incorporate E2E tests into pre-merge or post-merge pipelines depends on your testing strategies and available resources. Normally, E2E tests run in post-merge pipelines due to limited CI resources and testing devices.
Running E2E tests pre-merge needs to consider a few factors. The first one is the incurred pipeline time. You may consider running only a subset of your test cases, for example, those of core flows, to ensure the execution is time-bound. Another big question is how to judge whether a test failure is caused by the merge changes, or by flakiness. Setting up your CI pipelines in a way that E2E jobs are retry-able can help us co-live with flakiness. Also, having a tolerated threshold for the success rate would be helpful. For example, the pipeline could pass if at least 80% of the tests succeed.
5.4. Enhancing Troubleshooting Experience
Troubleshooting matters given the uncertainty of E2E testing.
Having a screenshot and recording after a test succeeds or fails is necessary. We can audit a test flow simply by looking at the recording and figuring out what went unexpected. Those screenshots and recordings are also useful for showcasing features.
Many failures occur due to incorrect element queries, such as wrong accessibility labels or IDs. A textual representation of the app hierarchy, in XML format - for example, would be very useful for debugging and improving element queries.
It is also helpful to extract app logs and related files (configs, database, etc.). This can be easily done with Appium’s pull file support.
Sometimes, we might encounter device issues or Appium-related problems. In such cases, collecting Appium logs, and WebDriverAgent logs (in iOS), would be necessary.
5.5. Test Retries
Retries are a common solution for flaky tests. However, in E2E testing where a test consumes quite some time, retrying a failed test means an additional amount of overall pipeline time. To mitigate this, we might consider retrying only certain types of failures.
6. Conclusion
Mobile E2E testing is critical yet challenging to ensure software quality. By choosing the right tools, frameworks, and strategies, you can effectively incorporate E2E testing into your engineering process. While tools like Appium offer flexibility and a rich ecosystem, the choice of framework, language, and execution model depends on your team’s needs and expertise.
This blog post has covered an overview and architectural considerations for E2E testing in the context of mobile development. Future posts will dive deeper into specific aspects, such as setting up device farms, mitigating flakiness, and integrating with CI/CD pipelines.
Stay tuned!
Like what you’re reading? Buy me a coffee and keep me going!
Subscribe to this substack
to stay updated with the latest content