1. Introduction
Flaky tests, known for producing inconsistent results (success or failure) over time, can be a source of frustration for developers. These non-deterministic tests can arise due to various factors, including code issues or an inconsistent testing environment. In this blog post, we will explore the concept of test quarantine, an approach to mitigate the challenges posed by flaky tests.
2. The Need for Test Quarantine
2.1. The Challenge of Flaky Tests
Flaky tests are particularly prevalent in certain types of testing, such as UI testing, where the higher level of integration introduces greater complexity. It's important to acknowledge that encountering flaky tests is an inevitable part of the testing process. And the key lies in how we manage and respond to them effectively.
2.2. What is Test Quarantine?
Test quarantine is a strategy for handling the outcomes of tests, especially when they exhibit flakiness. When a test is quarantined, it means that the success or failure of that test should not have a direct impact on the overall outcome of a test suite or job.
For example, consider a job that runs two tests: test1 and test2. If test1 succeeds while test2 fails but is identified as flaky, the job should still be considered successful, despite the failing result of test2.
2.3. The Importance of Test Quarantine
When a flaky test causes a failure in an engineer's merge/pull request, it can lead to frustration and wasted time. The failure may have nothing to do with the changes made by the engineer. Thus, it is crucial to identify and quarantine flaky tests, ensuring that job executions remain robust in the face of these flakinesses.
3. Designing Effective Test Quarantine Logic
3.1. Overview
The following diagram illustrates the core components of this approach.
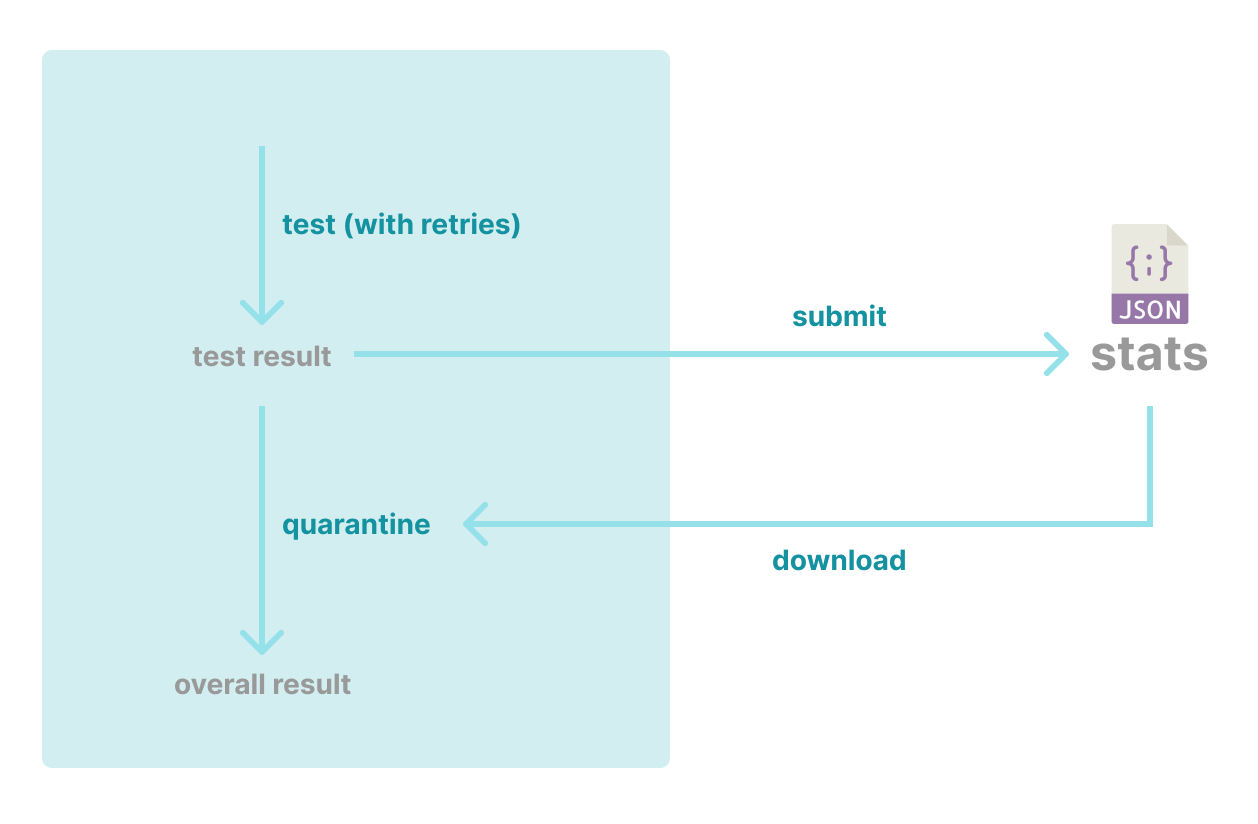 Fig. How quarantine logic is involved in deciding the overall result.
Fig. How quarantine logic is involved in deciding the overall result.
- Test result submission: The results of test executions are stored in a dedicated data store. This store could take the form of a separate Git repo, a database instance, or an S3 bucket.
- Statistical analysis: Is performed on the ingested data over a defined period (ex. 3 days) to determine the success rates of individual tests.
- Quarantine decision: When a test fails, the system fetches the relevant statistics and checks the corresponding success rate. If this success rate falls below a predefined threshold, the test is marked for quarantine. If all failed tests are identified as flaky, the job execution is considered a success.
3.2. Calculating Test Success Rates
The core of this approach hinges on ingesting test data and accurately calculating their success rates. This process resembles an ETL (Extract-Transform-Load) pipeline in data engineering.
There are various approaches for data ingestion, and Apache Airflow is a great choice for this purpose, providing scalable and manageable workflows.
 Fig. A sample DAG in Airflow UI.
Fig. A sample DAG in Airflow UI.
However, for iOS development, using Airflow may not be common due to unfamiliarity with Cloud-related tasks. Instead, we can use a Git-based solution as the desired ETL pipelines are fairly simple.
3.3. Git-based ETL Pipelines to Ingest Data
We create a dedicated Git repo to store test data, referred to as the “data repo”. When calculating the stats, we also store the result in this repo. Each change (ie. storing test data, or updating stats) corresponds to a Git commit.
A benefit of this Git-based approach is that engineers can easily intervene in the quarantine process. If a test suddenly becomes flaky, for instance, but its success rate is not yet updated, engineers can manually alter the stats data (ex. setting its success rate to 0.1) so that the quarantine takes effect immediately.
Receiving submission
In the data repo, we set up a pipeline/workflow that can be triggered from the main repo. When triggering such a pipeline, we pass the job ID of the pipeline running tests in the main repo. Related APIs:
- Github Actions: Create a workflow dispatch event.
- Gitlab CI/CD: Trigger a pipeline with a token.
main repo data repo
========= =========
test --- trigger (job id: ...) ---> receive submission
When receiving a submission from the main repo, we should not download test results right away because:
- There could be concurrent submissions at the same time, performing such updates results in a high chance of Git conflicts.
- The data repo is filled with lots of commits, making it grow in size drastically.
Rather, we should add the submission to a queue and later batch-download them. This queue indicates a list of job IDs to download test results.
Again, we wish to update the queue without any commit in the data repo. To achieve this, we can simply use a project variable to encode the queue.
TEST_DATA_SUBMISSION_QUEUE=11111,22222
Handling a submission now means updating the dedicated variable. Related APIs:
- Github Actions: Update an environment variable.
- Gitlab CI/CD: Update a variable.
The implementation of the submission handling looks like this (in Python):
def receive_submission(job_id):
key = 'TEST_DATA_SUBMISSION_QUEUE'
job_ids = job_ids_from_variable(key)
updated_job_ids = job_ids + [str(job_id)]
api.update_variable(key, job_ids_to_str(updated_job_ids))
def job_ids_from_variable(key) -> List[str]:
return [x for x in api.get_variable(key).split(',') if x]
def job_ids_to_str(job_ids) -> str:
return ','.join(job_ids)
Ingesting data
We can schedule this job to run hourly or every 30 minutes depending on your needs.
In this job, we perform a batch download of test results in the submission queue. For each job ID, we download the test result (in JSON) from the artifacts of the test pipeline in the main repo.
def download_test_results():
key = 'TEST_DATA_SUBMISSION_QUEUE'
job_ids = job_ids_from_variable(key)
for job_id in job_ids:
download_from_job(job_id)
...
updated_job_ids = set(job_ids_from_variable(key)).difference(job_ids)
api.update_variable(key, job_ids_to_str(updated_job_ids))
Data files are organized in the following structure for convenient queries.
data / <date> / <test_category>_<job_id>.json
|
|- 2023-01-01 / ui_tests_11111.json
| / unit_tests_22222.json
|
|- 2023-01-02 / ui_tests_33333.json
| / unit_tests_44444.json
Each file should have metadata about the job and pipeline to perform analysis on top of them.
{
"metadata": {
"ref": "main",
"pipeline_id": 12345,
"pipeline_status": true,
"job_id": 11111,
"job_status": true
},
"tests": {
"Tests/TestCase/testA1": false,
"Tests/TestCase/testA2": true,
"Tests/TestCase/testA3": true
}
}
Analyzing data
Once data has been ingested, the next step is to calculate relevant statistics. This task can be configured to run on a scheduled basis, perhaps once every few hours.
The stats calculation can be easily done with Pandas, a powerful Python library that simplifies the process of data analysis.
Loading Data into a DataFrame
When loading data into a DataFrame, we aggregate data over a specified period, such as the last 3 days, to gain a comprehensive view. The DataFrame structure resembles the following:
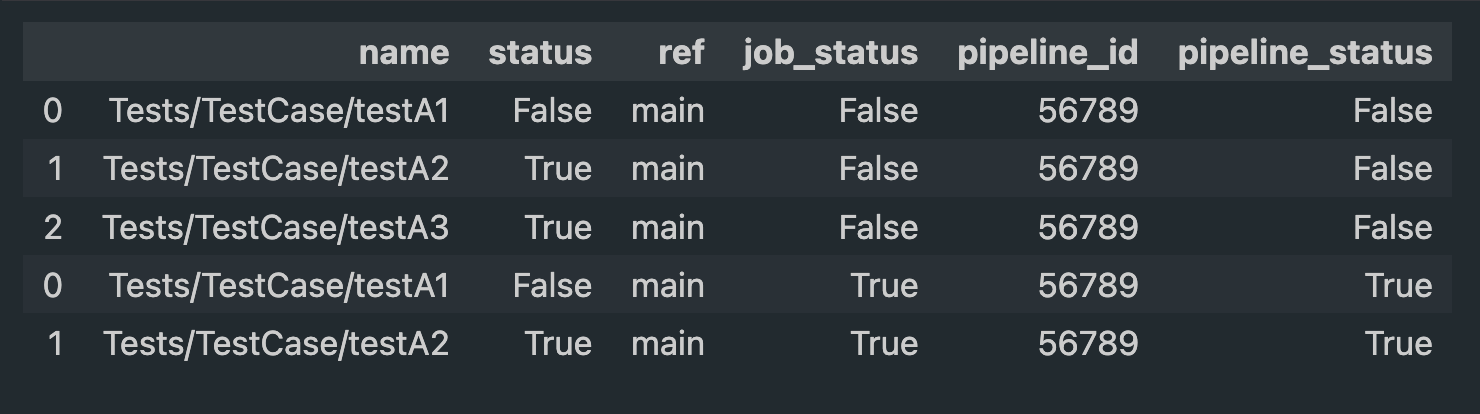 Fig. DataFrame of aggregated data.
Fig. DataFrame of aggregated data.
To achieve this, here's a sample Python code snippet to load data from corresponding JSON files, fill it with metadata, and concatenate the DataFrames:
import datetime
import glob
import json
import pandas as pd
def load_df(category: str, n_days: int = 3) -> pd.DataFrame:
def load(path) -> pd.DataFrame:
with open(path) as f:
data = json.load(f)
metadata, test_results = data['metadata'], data['tests']
df = pd.DataFrame([test_results]).T.reset_index()
df.columns = ['name', 'status']
df['ref'] = metadata['ref']
df['job_status'] = metadata['job_status']
df['pipeline_id'] = metadata['pipeline_id']
df['pipeline_status'] = metadata['pipeline_status']
return df
dfs = [
load(path)
for date in pd.date_range(end=datetime.date.today(), periods=n_days)
for path in glob.glob(f'data/{date.date()}/{category}_*.json')
]
return pd.concat(dfs) if dfs else pd.DataFrame()
df = load_df(category='ui_tests', n_days=3)
Filtering Relevant Data
Not all test executions should be included in the analysis. If a test fails on a merge request, the failure might be due to the change instead. Data in some following cases can be used:
- (1) Tests running on the main branch.
- (2) Tests of successful jobs.
- (3) Tests failing in one job but then succeeding after retrying that job. In this case, we just need to check whether the pipeline status is a success.
After excluding irrelevant data, we can group the DataFrame by test names and calculate the aggregated mean to obtain the success rates.
successful_pipeline_ids = set(df[df.pipeline_status].pipeline_id.to_list())
condition = (df.ref == 'main') \
| df.job_status \
| df.pipeline_id.isin(successful_pipeline_ids)
df = df[condition]
df_stats = df[['name', 'status']].groupby('name').mean()
df_stats.columns = ['success_rate']
# Export data to json file
with open('stats/ui_tests.json', 'w') as f:
json.dump(df_stats.to_dict()['success_rate'], f, indent=2)
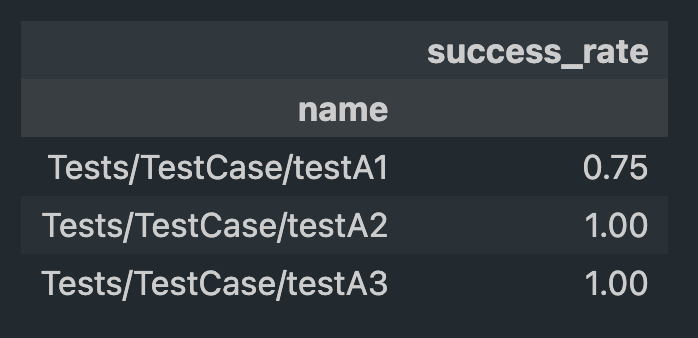 Fig. DataFrame of the calculated stats.
Fig. DataFrame of the calculated stats.
The output of this analysis is a JSON representation of the test success rates within the project, structured as follows:
{
"Tests/TestCase/testA1": 0.75,
"Tests/TestCase/testA2": 1,
"Tests/TestCase/testA1": 1
}
Keeping the data repo lean
As data accumulates over time, the data repo can quickly grow in size. A recommended best practice is to retain data for only the most recent N days. Removing outdated or stale data can be handled separately through scheduled jobs, or it can be integrated into the data ingestion process.
However, it's important to note that even after deleting stale files, they continue to exist within commits and as blobs, contributing to repo size. Since the commit history is not that important for this data repo, we can opt to replace all existing commits with a new one and then force-push the changes.
GIT_URL="$(git remote get-url origin)"
rm -rf .git
git remote add origin ${GIT_URL}
git commit -m "Reborn (triggered by job: $JOB_ID)"
git push -f origin HEAD
Avoiding Git conflicts
Given that a change in the data repo may come from different sources (an ingestion job, an analysis job, or a repo clean task), it’s essential to mitigate the risk of Git conflicts, especially when these jobs run concurrently.
One approach is to perform a pull-rebase prior to pushing changes. Another simpler solution is to set up job schedules at different times. For instance, we can schedule the ingestion job to run at the start of an hour (0 * * * *) and the analysis job to run 30 minutes after that (30 * * * *). As each execution typically takes less than 5 minutes, this scheduling strategy minimizes the chance of Git conflicts.
4. Conclusion
In this blog post, we've explored the concept of test quarantine as a powerful strategy to deal with flaky tests in iOS development.
The key components of such a test quarantine system include data ingestion, statistical analysis, and decision-making based on test success rates. The whole process from test data submission to stats generation is pretty much like an ETL pipeline, which can be solved by specialized tools such as Airflow or simply by a Git-based solution as mentioned.
The introduction of the quarantine logic establishes an automatic feedback loop within the development process:
- When a test becomes flaky, its success rate starts to decrease, triggering the test's quarantine.
- As the test stabilizes over time, its success rate gradually increases, eventually leading to the removal of the quarantine for that specific test.
This feedback loop ensures that tests are dynamically managed based on their reliability, promoting a more efficient and stable testing environment.
Resources
- Dealing With Flaky UI Tests in iOS: https://trinhngocthuyen.com/posts/tech/dealing-with-flaky-ui-tests
- Eradicating Non-Determinism in Tests: https://martinfowler.com/articles/nonDeterminism.html
- Airflow documentation: https://airflow.apache.org/docs
- Pandas documentation: https://pandas.pydata.org/docs